A base class for use in inheriting.
Codebase here: https://github.com/jed-gore/webcrawler_class
Something to save searches because I always forget the syntax for Beautiful Soup. I’ll be adding to this to handle encoding and error handling, and specific tags.
Remember: always scrape responsibly according to Terms of Service.
Includes a class WebCrawler with 3 simple methods: get_html_document() get_links() and get_tables()
Usage:
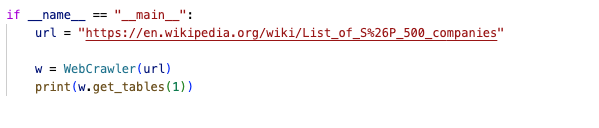
Output:

Also includes a c.py file to handle certification updates for Mac’s with fresh python installs so pandas’ read_html works on a Mac.